Features
Everything a production queue needs. Nothing it doesn't.
Built ground-up in Go. No dependencies, no configuration sprawl.
Native scheduled delivery
Set deliver_at to any future UTC millisecond. An in-memory Min-Heap (O(1) peek, O(log N) insert) fires messages precisely when due — no database polling loop.
At-least-once delivery
Visibility timeouts lock messages while in-flight. If your consumer crashes without ACKing, the message becomes ready again automatically.
Dead-letter queue
Every queue gets a paired DLQ. Failed messages land there after max_retries. Inspect and replay with a single API call.
Three consumer models
HTTP poll, WebSocket push (with backpressure), or Webhook delivery — pick what fits your architecture. Mix and match per queue.
Durable storage
Append-only WAL + bbolt index. On restart the WAL is replayed to restore all state exactly as it was. Default fsync=interval (1 s) — for zero data loss on a hard crash set fsync=always. Durability details →
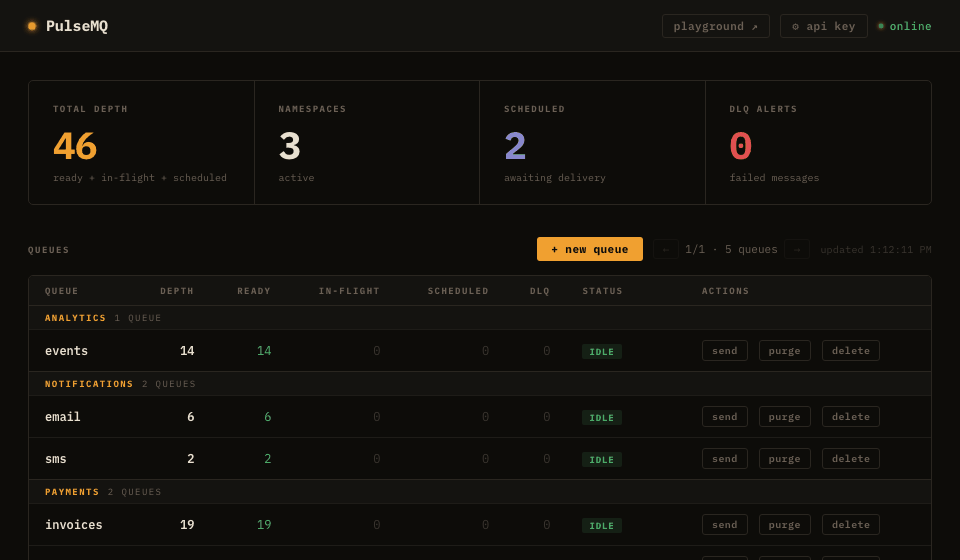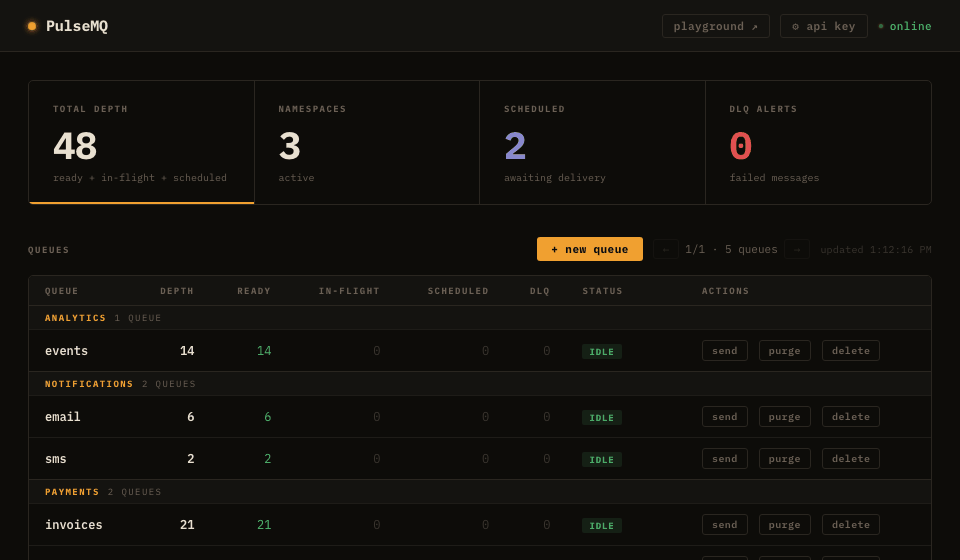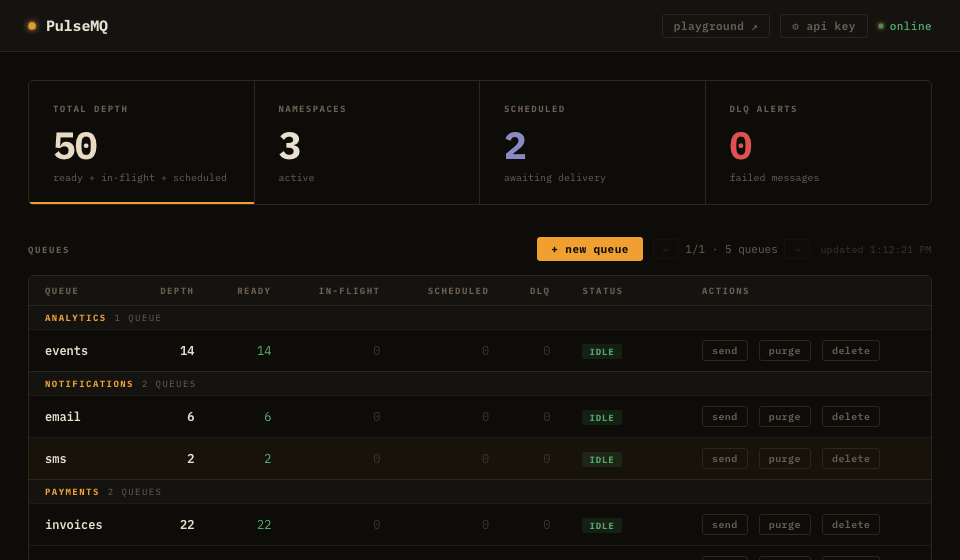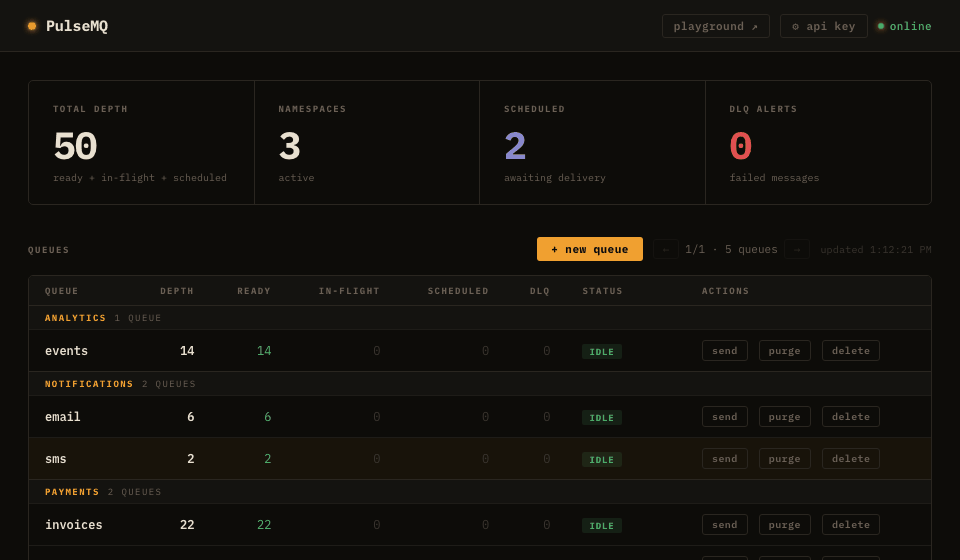
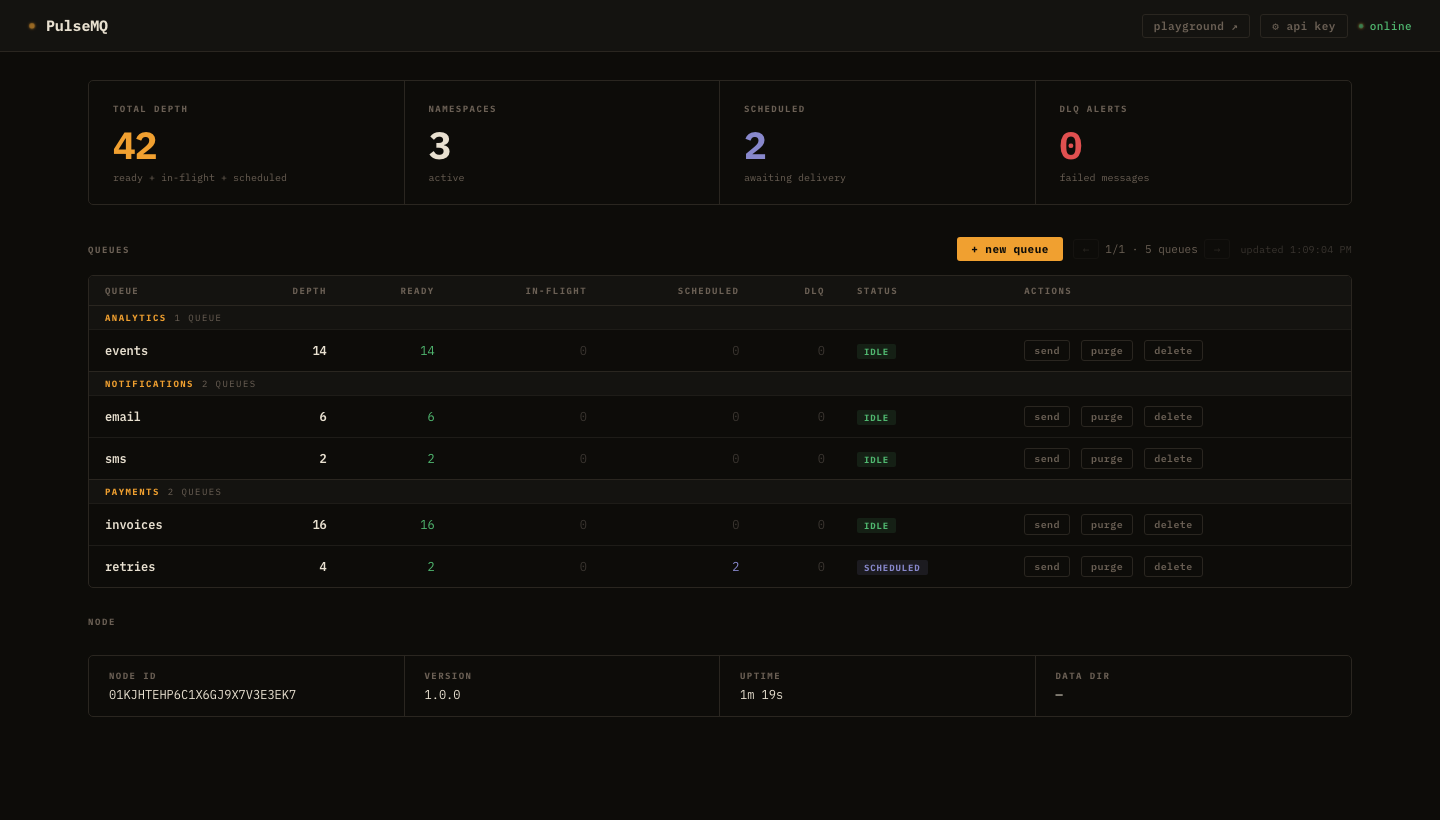
Built-in dashboard
Live queue depths, scheduled counts, DLQ alerts, pagination for 500+ queues. Create queues, send messages, replay DLQ — all from the browser.
Prometheus metrics
Published, consumed, ACKed, NACKed, DLQ-routed counters per queue. HTTP request latency histograms. Scrape from port 9090.
Auth + rate limiting
Static API key via X-Api-Key header. Per-IP token-bucket rate limiter and request body size cap built in.
Single-node v1 · Raft on the roadmap
v1 runs as a single node. 3-node Raft cluster support is on the roadmap — and the WAL format already carries Raft term + log_index fields, so the storage format won't change when clustering ships.